Table of Contents
世の中の関数型言語と呼ばれるプログラミング言語は、ほぼ間違いなく高階関数(higher order
function)というものを備えています。以前述べたように関数型言語は関数の扱いに特化しており、関数を第一級オブジェクトとして扱うことができます。したがって、int型などのごく普通の値と同じように変数に代入(識別子に束縛)したり、関数の引数として渡したり、戻り値として返したりすることができます。
高階関数とは、このように関数値を引数にとったり戻り値として返したりすることができる関数のことをいいます。C#でもdelegateを受け取って、処理を部分的に委譲するような関数がありますが、高階関数はそれに似ています。
関数型言語では、よく高階関数とラムダ式とを組み合わせて使います。ここではそのいくつかの例を紹介します。とくにリストや配列などのデータ構造に対してデータ処理を行う場合には、高階関数が非常に役立ちます。
F#に標準で組み込まれているライブラリには、さまざまな高階関数が用意されています。とくに便利なのが、リストや配列などに対する高階関数です。いくつか例を見てみましょう。
> List.map (fun x -> x + 1) [1..5];; val it : int list = [2; 3; 4; 5; 6] > List.filter (fun x -> x % 2 = 0) [1..5];; val it : int list = [2; 4] > List.partition (fun x -> x % 2 = 0) [1..10];; val it : int list * int list = ([2; 4; 6; 8; 10], [1; 3; 5; 7; 9])
List.mapは、1から5のすべての要素に対して、1を加算する関数を適用します。一方、List.filterは1から5の中から2で割り切れる数(すなわち偶数)を抽出します。最後のList.partitionは、リストの要素を2で割り切れる(偶数)リストとそうでない(奇数)リストに2分割します。これらの関数は第1引数に関数を受け取る関数であるため、このList.mapとList.filterとList.partitionは高階関数であるといえます。
このmapとfilterは非常によく使われる高階関数で、他の関数型言語でもこれらに相当するものは当たり前のように用意されています。
ここではリストに対する高階関数を紹介しましたが、配列やほかのデータ構造に対しても同じようなものが用意されています。後の章では、リストに対する高階関数のしくみについて詳しく解説します。
ちなみに、上のList.mapの例で出てくる(fun x -> x +
1)というラムダ式は、前章の演算子のところで説明した構文を使うともう少し短く書くことができます。
> List.map ((+) 1) [1..5];;
val it : int list = [2; 3; 4; 5; 6]
Note
中置演算子は()で囲むと普通の関数のように扱うことができたことを思い出してください。
> 1 + 2;; // 中置演算子として呼び出す val it : int = 3 > (+) 1 2;; // 普通の関数のスタイルで呼び出す val it : int = 3 > (+) 1;; // 第1引数だけ部分適用して1を加算する関数を作り出す val it : (int -> int) = <fun:clo@0>
最後に、F#でよく使われる高階関数(もとい演算子)を紹介します。それはパイプライン演算子(pipeline operator)と呼ばれる演算子です。といっても、この演算子自体は何か特別なことをするわけではなく、単に1引数関数の関数呼び出しにおける、関数と引数の順番を入れ替えるだけのはたらきをします。
> let plus10 x = x + 10;; // まずは単純な1引数の関数を定義 val plus10 : int -> int > plus10 100;; // 関数をごく普通に呼び出す val it : int = 110 > 100 |> plus10;; // パイプライン演算子を使って、関数呼び出しにおける関数と引数の順番を入れ替える val it : int = 110
上のプログラムにおける|>という中置演算子がパイプライン演算子です。通常は、
function-name
argument
というふうに、関数名に続けて引数を並べることで関数が呼び出されます。しかしパイプライン演算子を使う場合は、
argument |>
function-name
というふうに、演算子の左側に引数、右側に関数値を与えることで関数が呼び出されます。この演算子は演算子の右側の引数として関数値をとるので、高階関数であるといえます。ところで、この演算子はどういう使い道があるのでしょうか。それは次の例のように、関数を連続して適用する場合の処理の流れを、明確にすっきりと書くために使います。
> 100 |> plus10 |> (*) 2 |> plus10;; // 100に10を足して、2を掛けて、最後に10を足す val it : int = 230 > plus10 ((plus10 100) * 2);; // パイプライン演算子なしで書く val it : int = 230
この例のように、パイプライン演算子を使うと処理の順番が明確になります。といっても、この例だけはよくわからないと思いますので、もうすこし現実的な例をいくつか示します。
> [1..100] |> List.filter (fun x -> x % 3 = 0 && x % 5 = 0) |> List.length;; // 1から100までの整数のうち3と5の倍数がいくつあるか数える val it : int = 6 > List.length (List.filter (fun x-> x % 3 = 0 && x % 5 = 0) [1..100]);; // パイプライン演算子を使わないバージョン val it : int = 6 > 'A' |> int |> (|||) 0x20 |> char;; // 大文字→小文字変換('A'をアスキーコードに変換→下位6ビット目を立てる→文字にもどす) val it : char = 'a' > char (int 'A' ||| 0x20);; // パイプライン演算子を使わないバージョン val it : char = 'a' > sin (1.5 * 3.14) * 20.0 + log(8.718) |> int;; // float値で複雑な計算を行った結果を最終的にintに変換する val it : int = -17 > int (sin (1.5 * 3.14) * 20.0 + log(8.718));; // パイプライン演算子を使わないバージョン val it : int = -17
これらの例のように、リストや配列のデータの各要素をフィルタリングしたり加工する際や、型を変換する場合によく使います。とはいうものの、どちらのコードがわかりやすいかには嗜好があるため、最終的には好みの問題になってしまいますが、F#ではよく使われるため慣れておいたほうがよいでしょう。
まずは以下の例を見てください。
> let rec accumulate_plus n result = match n with | 0 -> result | _ -> accumulate_plus (n-1) (result+n) let rec accumulate_mult n result = match n with | 0 -> result | _ -> accumulate_mult (n-1) (result*n);; val accumulate_plus : int -> int -> int val accumulate_mult : int -> int -> int > accumulate_plus 5 0;; // 1+2+3+4+5 val it : int = 15 > accumulate_mult 5 1;; // 1*2*3*4*5 val it : int = 120
accumulate_plusとaccumulate_multは、それぞれ0~nまでの数値をすべて足す関数とすべて掛ける関数です。2番目と3番目の入力では、それぞれ1から5までの和と積を計算しています。ただし、和のほうはresultに初期値として0を渡し、積のほうは1を渡していることに注意してください。
この2つの関数は非常によく似ており、違うところは一番最後の(result+n)と(result*n)だけです。この足し算も掛け算も、両方とも2つのintを受け取ってintを返す関数、すなわち(int
-> int ->
int)という型をもつ2引数関数です。この部分の処理を外部の関数に任せてしまう高階関数を定義します。
> let rec accumulate f n result =
match n with
| 0 -> result
| _ -> n * accumulate_mult (n-1) (f result n);;
val accumulate : (int -> int -> int) -> int -> int -> int
新たな引数としてfを導入しました。応答を見てみると、fの型は(int
-> int -> int)となっています。
この関数を使って、accumulate_plusとaccumulate_multを定義することができます。
> let accumulate_plus n result = accumulate (+) n result;; val accumulate_plus : int -> int -> int > let accumulate_mult n result = accumulate (*) n result;; val accumulate_mult : int -> int -> int
accumulate_plusは(+)という関数を、accumulate_multは(*)という関数を内部で利用しています。このように、関数を引数にとっているため、accumulateは高階関数となります。
このaccumulateの例では、高階関数の便利さはあまり伝わらないかもしれません。後の章では、このaccumulateをさらに一般化した、畳み込み(fold)という操作を行う高階関数を定義します。この畳み込みというものは大変便利で、F#にも標準ライブラリの中に組み込まれています。
たいていのリストの処理は、先ほど紹介したmapとfilterとfoldを使って表現できます。これらを使って表現すると、面倒な再帰関数を自分で定義する必要がなくなります。
述語(predicate)とは、1つ以上の引数を受け取りtrueかfalseを返す関数のことをいい、特にn個の引数をとる述語をn項述語といいます。自分で定義した関数内で、一部の判断を外部に委ねたいときに、この述語を使うことができます。
次の例は0から100までの数の中で、ある条件を満たすものの数を数えます。関数counterは条件判断を述語predに委ねる高階関数です。
> let rec counter pred n result = match n with | 0 -> result // 合計数resultを返す | _ -> let new_result = if (pred n) then result+1 else result counter pred (n-1) new_result // 現在の値を減らして再帰呼び出しする let count_if pred = counter pred 100 0;; val counter : (int -> bool) -> int -> int -> int val count_if : (int -> bool) -> int > count_if (fun n -> n % 2 = 0);; // 2で割り切れる数を数える val it : int = 50 > count_if (fun n -> n % 5 = 0);; // 5で割り切れる数を数える val it : int = 20
counterは0から100までの値を述語predに渡して、それが述語を満たす(trueを返す)場合は、resultに1を足したものをnew_resultとし、そうでなければresultをそのままnew_resultとします。そして、最後に0に到達したら(base
case)最終的なresultを返します。count_ifは単純に、カウンタの初期値nに100、合計数resultに0を与えたcount関数をくるんで使いやすくしただけのものです。
2番目と3番目の入力では、述語として2で割り切れる数と3で割り切れる数かを判断する述語を与えています。
-
以下の関数うち、高階関数はどれでしょうか。
-
filter_odd : int list -> int list -
transform : (float -> float) -> float array -> float -> array -
find_file : string -> string -> string list -
message_box : (unit -> string) -> DialogResult -
message_formatter : int -> (string -> string)
-
-
高階関数の定義を述べてください。
-
以下の関数のうち、述語はどれでしょうか。また、それが述語だった場合、何項述語であるかも答えてください。
-
is_odd : int -> bool -
compare : string -> string -> bool -
larger : float -> float -> float -
is_neighboring : float * float -> float * float -> bool -
create_predicate : int -> (int -> bool)
-
-
述語の定義を述べてください。
-
以下のプログラムは、クイックソートを行うプログラムです。クイックソートとは有名なソートアルゴリズムで、以下の手順によってソートを行います。
-
リストから適当な要素xを1つ抜き取る。
-
そのリストの各要素とxを比較し、xよりも大きい値のリストと小さい値のリストの、2つのリストを作る。
-
小さい値のリストと大きい値のリストに対して再帰的にクイックソートを行い、最後にそれらを順番に連結する。
let rec qsort lst = match lst with | x::xs -> let smaller,bigger = List.partition (fun n -> n < x) xs qsort smaller @ [x] @ qsort bigger | _ -> []このプログラムでは、大小の判断を述語
(fun n -> n < x)で表現していますが、以下のように引数として外部から任意の述語を渡せるような関数qsort_ : (int -> int -> bool) -> int list -> int listを定義してください。> qsort_ (<) [3;51;0;10];; val it : int list = [10; 51; 3; 0] > qsort_ (>) [3;51;0;10];; val it : int list = [0; 3; 10; 51]
Note
C言語でクイックソートをここでは書いたことがある人は、このプログラムの簡潔さに驚いたかもしれません。ただし、このプログラムは見易さを優先して書いているため、実行効率は多少犠牲になっています。
-
-
(数学が嫌いな人はできなくても大丈夫です)
関数
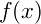 の導関数
の導関数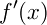 は、以下の式で定義されます。
は、以下の式で定義されます。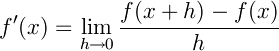
この定義式をそのまま使い、関数
f : float- > floatを受け取り、その(近似的な)導関数を返す高階関数deriveを定義してください。ただし、hの値は10-10として計算してください。この関数の実行例は以下のようになります。> open System;; // Math.PIを使うため > let my_cos = derive sin;; // 組み込みの三角関数sinをderiveで微分して、独自のcosを作る val my_cos : (float -> float) > cos Math.PI;; // 組み込みのcos val it : float = -1.0 > my_cos Math.PI;; // 独自のcos val it : float = -1.000000083 > cos Math.PI/2.0;; // 組み込みのcos val it : float = -0.5 > my_cos Math.PI/2.0;; // 独自のcos val it : float = -0.5000000414 > cos Math.PI/4.0;; // 組み込みのcos val it : float = -0.25 > my_cos Math.PI/4.0;; // 独自のcos val it : float = -0.2500000207
ある関数値が、自分の外で定義されているローカルな値(すなわちトップレベルでない値)を参照している場合、その関数値のことを特別にクロージャ(closure)と呼びます。まずは以下の例を見てください。
Note
前章の部分適用のところで説明したように、クロージャとは実行時に作られる動的なものであることに注意してください。
> let func_value = // クロージャでない普通の関数値(ラムダ式の外部の識別子は参照していない) (fun x -> x + 5);; val func_value : int -> int > let closure = // クロージャ(ラムダ式の外側で定義されたローカル値fiveを参照) let five = 5 (fun x -> x + five);; val closure : (int -> int) > func_value 5;; // 戻り値として返された関数値に対して、5を渡して呼び出す val it : int = 10 > closure 5;; // 戻り値として返された関数値(クロージャ)に対して、5を渡して呼び出す val it : int = 10
func_valueもclosureのどちらも、ラムダ式によって関数値を作り、それを返しています。ひとつ違うのは、closureがラムダ式の外で定義されたローカルな識別子fiveの値を参照しているところです。このように、自分の外で定義されたローカルな値を参照するラムダ式によって作り出される関数値を、プログラミング言語論ではクロージャと呼びます。
ここで、クロージャという概念をはじめて聞いた方は、自分の外部の識別子の値を参照できるなんて当然のことで、なぜクロージャなどといって特別視するのか疑問に思ったかもしれません。これは利用する側からは大した違いではないように見えますが、実は大きな違いがあります。
F#では、ある関数値が外部のローカル値を参照している場合(すなわちその関数値がクロージャの場合)、その関数値が呼び出されるたびに毎回その識別子の内容を見に行きます。したがって、プログラムの実行されているあいだ、クロージャはその識別子の情報を常に保持しつづけ、必要になるたびに毎回その値を見に行くという動作をします。また、参照する識別子がローカルな値を指しているという点も重要です。もしそれがトップレベルの値ならば、そのスコープはプログラム全体であり、いつでも手軽にその値にアクセスできます。しかしローカルな値の場合、クロージャはその値への参照を保存しておかないと、後で見にいくことができなくなってしまう上に、場合によっては破棄されてしまうおそれもあります。
このような実装上の理由により、クロージャは普通の関数と比べて多少コストがかかります。しかし実際は、その外部の値が変化しないことが保障されている場合は、最適化によってコンパイル時に定数に置き換えられることが期待できます。しかし、その値が変化する可能性がある場合は、最適化は期待できません。今までは、一度束縛した識別子の値は変化することはないと説明してきましたが、後の章の命令型プログラミングのところでは、内容の書き換えが可能な識別子も出てきます。その外部の識別子の値が書き換え可能である場合、関数が呼び出されるときにならないと、その識別子の内容を知ることはできません。すなわち、プログラムの実行時においても、常にその識別子が指すメモリアドレスを保持しておき、関数が呼び出されるたびに毎回そのメモリアドレスを見に行かなければなりません。
この節ではクロージャを詳しく理解するために、まずプログラミング言語論における環境という概念を説明し、その概念を用いてクロージャの説明をします。
プログラミング言語論には、環境(environment)という概念があります。環境とは、現在の場所からアクセスできる識別子の集合を意味します。といっても何のことだかわからないと思うので、以下のプログラムで考えてみましょう(便宜的に行番号をつけています)。
1:let a = 0 2: 3:let f () 4: let b = 10 5: a + b 6:
たとえば、このプログラムの5行目の時点でアクセスできる識別子は何でしょうか。この場合は、aとbの2つの識別子です。ほかの行も考えてみると、2行目ではa、6行目ではaとfといった具合に、各地点においてアクセスできる識別子の集合が異なるのがわかります。
これを整理して、各行の先頭における環境をまとめてみると以下のようになります。(厳密にいうと1行は「なし」ではなく、F#側が容易してくれるデフォルトの環境があります。このデフォルトの環境は、F#標準ライブラリ内のさまざまな関数の識別子を含んでいます。2行目以降も同様です。)
1: なし 2: a 3: a 4: a 5: a,b 6: a,f
このように、各地点においてそこからアクセスできる識別子の集合を、その状況を取り巻くものという意味で環境とよびます。
ラムダ式は関数値を作り出します。そしてその関数値には、適当な名前を束縛しておいて、後からそれを呼び出すことができます。もしその関数値がクロージャだった場合は、クロージャが保持している外部の識別子の値を参照しにいく必要があります。この外部の識別子の参照が発生するのは、クロージャが作られる時ではなく、実際にその関数値が呼び出される時です。したがってクロージャは、呼び出されるまでその外部の識別子に関する情報をずっと保持している必要があります。
この「外部の識別子に関する情報」というのが、まさに環境を意味します。クロージャは、ラムダ式によって作り出された時点での環境を保存しており、後から呼び出されるときは、保存しておいた環境を使って外部の識別子が指す値を参照しにいきます。このことを例を用いて説明します。
> let f = let v = 5 (fun x -> x + v);; val f : (int -> int) > f 10;; val it : int = 15
1番目の入力では、ラムダ式によって関数値を作り出し、それを戻り値として返します。このラムダ式の内部では、外側で宣言されているvという局所的な識別子の値を参照しているため、作り出される関数値fはクロージャになります。このクロージャfを作る時点では、vに関する情報を保存するだけでその中身を見に行きません。そして、2番目の入力でクロージャを呼び出したときに、初めてそのvの値を取り出して足し算を行います。
Note
実際にコンパイルされたアセンブリを見てみると、クロージャはFastFuncというクラスの派生クラスとして実装されています。そして、クロージャが作られるときは、FastFuncのコンストラクタが呼ばれ、その引数には参照している識別子の情報が渡されてインスタンス変数へと保存されます。
以上のことから、クロージャは関数値と環境がペアになったものであることがわかります。関数型プログラミングでは、識別子が指す値は基本的に変わらないため、いつその値を参照しても問題にはなりません。しかし、後で紹介する命令型プログラミングの可変データを扱う場合は、参照するタイミングによって値が変わる可能性があります。そのようなときは、今回説明したクロージャの動作原理の知識が必須となります。
節の冒頭で説明したように、クロージャは通常の関数と違って多少のコストがかかります。ところが通常の関数とクロージャは、呼び出し方だけ見ると違いがわかりません。したがって、意識しない限りはどちらであるかに気付きません。その例を少し見てみましょう。
> let plus10_ = // クロージャを生成 let value = 10 fun x -> x + value;; // ラムダ式の外の識別子valueを参照 val plus10_ : (int -> int) > let plus10 = // 通常の関数を生成 fun x -> let value = 10 x + value;; // 識別子valueはラムダ式内部で定義したもの val plus10 : int -> int > plus10_ 5;; // クロージャを呼び出す val it : int = 15 > plus10 5;; // 通常の関数を呼び出す val it : int = 15
まず、1番目の入力では関数値を生成してplus10_という識別子を束縛しています。このラムダ式は、外部で定義されているローカルな識別子valueを参照しているためクロージャです。2番目の入力も同じような書き方でラムダ式によって関数値を生成しています。ここでもvalueという識別子を参照していますが、この識別子はラムダ式の内部で定義したものなので、この関数値はクロージャではありません。
ちなみに、前章のカリー化のところでの「F#のn引数の関数は、1引数ラムダ式のn重の連鎖と等価である」という説明を覚えているでしょうか。これを逆にいうと「F#の1引数ラムダ式のn重の連鎖は、n引数の関数と等価である」ということになります。すなわち、plus10は以下のように書き換えることができます。
> let plus10 x = // 上記のラムダ式による定義と等価な定義 let value = 10 x + value;; val plus10 : int -> int
この定義を見ると、plus10は実際にはF#における通常の関数に過ぎないことがわかります。
さて、もう一度最初の例の説明に戻ります。3番目と4番目の入力では、それぞれ上で定義したクロージャplus10_と通常の関数plus10を呼び出しています。このように、両者は呼び出す側からは見ると、どちらがクロージャでどちらが通常の関数なのかは判別できません。
しかし、冒頭でも述べたようにクロージャには多少のコストがかかるため、不必要なクロージャの生成は避けるべきです。生成された関数値がクロージャかどうかを簡単に見分ける方法はないのでしょうか。実は型に注目するとそれを判別することができます。もう一度最初の例に戻って、F#
Interactiveからの応答として返されたplus10_とplus10の型をよく見比べてください。先ほどは気づかなかったかもしれませんが、クロージャのほうは型の文字列全体が括弧で囲われていることがわかります。これがF#においてクロージャを見分ける方法です。
ところでこの節で紹介する以前に、クロージャが出てきたのを覚えているでしょうか。忘れた方は、前の章の部分適用の説明を読み直してみてください。そこでクロージャで紹介したクロージャの定義は「それまでに与えられた引数と残りの必要な引数の情報を付加した関数値」でした。ところが、この章で紹介したクロージャの定義は「外部のローカルな値への参照情報を付加した関数値」です。これはどういうことなのでしょうか。
実はこれらはF#における狭義のクロージャの定義で、広義のクロージャの定義は「関数値+その外部で定義された値に関する情報」ということになります。ほかの言語におけるクロージャを知っている方は、この定義を不思議に思ったかもしれませんが、クロージャの定義はプログラミング言語ごとに微妙に異なります(WikipediaのClosureを参照)。
Warning
現在のF#のドラフト言語仕様(spec-1.9.6-v5)では、クロージャに関する明確な定義はありません。ここで述べたことは、現在の言語仕様やコンパイルされたアセンブリや書籍(Expert F#,、F# for Scientists)の情報をもとに暫定的に定義したものです。
先ほどから説明しているように、クロージャはにコストがかかります。したがって、もし無駄にクロージャが生成されてしまった場合は、通常の関数に書き換えるべきです。そこで、どのようなときにクロージャが生成されるのかを改めて整理してみましょう。F#では、少なくとも以下の場合にクロージャを生成します。
-
外部のローカルな値を参照している関数値を生成する場合(そのローカルな識別子の情報を保存するため)
-
部分適用により新たな関数値を生成した場合(現在まで与えられた引数の情報と呼び出しに必要な残りの引数の情報を保存するため)
Note
上記の条件から外れる場合でもクロージャができることがあります。たとえば以下のコードでは、ラムダ式の内部でzを参照していないのでクロージャを作る必要はないはずです。ところが、現在のF#のバージョン(1.9.6.2;
September 2008 CTP)でも、クロージャを生成してしまいます。
> let f =
let z = 3
(fun x -> x + 10);;
val f : (int -> int)
-
以下の式はそれぞれ関数値を生成しますが、そのうちクロージャを生成するのはどれでしょうか。ただし、これらの式はすべてトップレベルから始まっているとします。
-
let comparator = let x = 0 (fun n -> n < x)
-
let value = 10 let plus10 = fun x -> x + value
-
let plus = fun x -> fun y -> x + y
-
let plus10 = fun x -> let v = 10 fun y -> x + y + v
-
let plus10 = let v = 10 fun x -> fun y -> x + y + 10
-
let plus = (+)
-
let plus x y = x + y
-
C# 2.0からは、新たにジェネリック(generic)という機能が追加されました。ジェネリックを使うと、何らかの型を型パラメータ(type parameter)として受け取り、その型パラメータに応じたクラスおよびメソッドを生成することができます。復習もかねてC#での例を見てみましょう。
class ReadOnlyArray<T>
{
readonly T[] _array = null;
public ReadOnlyArray(T[] array)
{
_array = array;
}
public int GetLength()
{
return _array.Length;
}
public T GetAt(int index)
{
return _array[index];
}
}
class Program
{
static void Main(string[] args)
{
ReadOnlyArray<int> IntArray = new ReadOnlyArray<int>(new[] { 100, 23, 3832 });
ReadOnlyArray<string> StringArray = new ReadOnlyArray<string>(new[] { "hello", "world" });
int x = IntArray.GetAt(2); // 3832が代入される
string y = StringArray.GetAt(0); // "hello"が代入される
}
}
このReadOnlyArrayはジェネリックなクラスです。ReadOnlyArrayのあとにTという名前が指定されており、このTにはintやdoubleやDateなどの任意の型を指定することができます。このように、Tは変数のようなはたらきをするので、型パラメータ(type
parameter)や型変数(type variable)などと呼ばれます。
一度Tに型を指定すると、指定された型をもつインスタンスが生成されます。たとえば上の例だと、ReadOnlyArray<int>では、Tがintで置き換わったReadOnlyArrayクラスのインスタンスが生成され、ReadOnlyArray<string>でも同様に、Tがstringで置き換わったものが生成されます。
Note
ジェネリックは、C++におけるテンプレートという機能をもとに作られました。実際、このふたつの構文は非常によく似ています。ところが、よく調べてみると、ジェネリックとテンプレートには多くの違いがあり、それぞれできることとできないことがあります。
前章のNoteではC++のテンプレートメタプログラミングの世界について説明しましたが、ジェネリックにはテンプレートほどの柔軟性はありません。しかし逆に、ジェネリックにおける型制約など、テンプレートではできないこともあります。
これらの構文はよく似ていますが、そもそも実装の仕組みは根本的に異なります。テンプレートはコンパイル時に完全に処理され、実行時にはテンプレートに関する情報は残りません。一方、ジェネリックはコンパイル時だけでなく、実行時にもその情報を保持します。
F#ではC#よりも積極的にジェネリックを使います。したがって、F#のプログラミングスタイルでは型推論を積極的に活用し、冗長な型の指定を省略します。たとえば、2つのint型のうち大きいほうを返す関数maxを書けといわれた場合、F#とC#における一般的なプログラミングスタイルに従って書くと以下のようになります。
// C#
class Numeric {
public static int max(int x, int y)
{
return x > y ? x : y;
}
}
// F#
let max x y = if x > y then x else y
このようにC#では引数・戻り値どちらもintと明示的に書くのが普通ですが、F#では型指定を省略するのが普通です。C#でもいきなりジェネリックを使ってmaxを定義する人もいるかもしれませんが、非常に煩雑になるため、簡易的に書けといわれた場合は使わないのが普通です。実際、ジェネリックを使うと以下のようになってしまいます。
class Numeric
{
public static T max<T>(T x, T y) where T : System.IComparable<T>
{
return x.CompareTo(y) > 0 ? x : y;
}
}
特に今回は比較演算子>を使っているため、型変数Tに対して型制約(where
T : System.IComparable<T>)が必要となって非常に煩雑です。
Note
比較演算子はすべての型やクラスで使えるわけではありません。たとえば、ファイルから文字列を読み込むStringReaderクラスどうしを比較演算子で比較することはできません。
しかし上記のF#の関数は、型推論により意識しなくてもジェネリックな関数となります。型推論は可能な限りジェネリックな形に推論します。F#の型推論を積極的に使うという慣習が、ジェネリックを積極的に使うということにつながるのです。
では、実際にどのように型推論されるかを見てみましょう。
> let max x y = if x > y then x else y;;
val max : 'a -> 'a -> 'a
この'aというものが型変数です。F#では型変数名はアポストロフィーで始まる文字列で表されます。ここで型アノテーションによって明示的に引数の型を指定すると、'aには指定した型名が入ります。
> let max (x:int) (y:int) = if x > y then x else y;;
val max : int -> int -> int
型の指定は部分的でもかまいません。たとえば、第1引数のみ型を指定してみます。
> let max (x:int) y = if x > y then x else y;;
val max : int -> int -> int
すると、第2引数と戻り値の型も自動的にintと決定されてしまいました。これは型推論によって自動的に決定されたものです。
型推論は、矛盾が起きない範囲でもっとも汎用的な型に推論しようとしますが、この場合は第2引数も戻り値もintにしかなりえないためintに決定されました。実際、第2引数と戻り値がint以外の型にはなりえません。
さらに別のケースを見てみましょう。
> let make_tuple x y = x, y;;
val make_tuple : 'a -> 'b -> 'a * 'b
これは2つの引数を受け取り2組のタプルを作る関数です。タプルの2つの要素は同じ型である必要はないため、2つの異なる型変数を使う汎用的な型に推論されました。ここで、以下のように自分で型変数を使用して、2つの要素が同じ型となるように型を指定することもできます。
> let make_tuple (x:'a) (y:'a) = x, y;; // xとyの型が同じになるように指定する val make_tuple : 'a -> 'a -> 'a * 'a > let make_tuple (x:'type_name) (y:'type_name) = x, y;; // 上と同じ(型変数名だけが異なる) val make_tuple : 'type_name -> 'type_name -> 'type_name * 'type_name
型変数名は慣習的に'a、'b、'c…とするのが普通ですが、2番目の入力のように、自分で好きな名前をつけることも出来ます。
F#では、この型変数を利用してジェネリックなメンバを持つレコード型やdiscriminated unionなどを定義することができます。
> type Point<'a> =
{ X : 'a;
Y : 'a };; // 'a型のメンバXとYをもつレコード型
type Point<'a> =
{X: 'a;
Y: 'a;}
> let p = { X = 1.0; Y = 3.0 };; // Point<float>のインスタンスを作る
val p : Point<float> = {X = 1.0;
Y = 3.0;}
> let p = { X = 20u; Y = 32u };; // Point<uint32>のインスタンスを作る
val p : Point<uint32> = {X = 20u;
Y = 32u;}
自分でジェネリックな型を定義する場合、型名の直後に利用する型変数をカンマで区切って並べ、それを<>で囲います。ここでは、まず'aという型変数のメンバをもつレコード型であるPointを定義し、2番目と3番目の入力で実際にそのインスタンスを生成しています。ここでは、インスタンスの生成時に明示的にPoint<float>などの型名を指定しませんでしたが、型推論のおかげで意図した型のインスタンスが正しく生成されています。
F#には、以下のジェネリック比較演算(generic comparison)というものが定義されています。
val compare : 'a -> 'a -> int val (=) : 'a -> 'a -> bool val (<) : 'a -> 'a -> bool val (<=) : 'a -> 'a -> bool val (>) : 'a -> 'a -> bool val (>=) : 'a -> 'a -> bool val (min) : 'a -> 'a -> 'a val (max) : 'a -> 'a -> 'a
これらは値同士の比較を行う演算ですが、C#にも同じような関係演算子(<、>、<=、>=)が定義されています。ただし、これらはC#の関係演算子とは別物で、性質が少し異なります。
C#の関係演算子は数値型と列挙型のみに定義されており、自分で定義したクラスや構造体で使う場合は、自分でその演算子を定義しなければなりません。
しかしF#のジェネリック比較演算は、複合型であっても自動的に比較を行ってくれます。この自動的な比較では、複合型のメンバ同士をひとつずつ比べ、全てが等しければ複合型全体も等しいという判断をします。この自動的な比較演算は、複合型のメンバをひとつずつ取り出して調べていくため、構造的比較演算(structural comparison)とよばれます。実際に例を見てみましょう。
> ("abc","def") < ("abc","xyz");; val it : bool = true > compare (10,30) (10,30);; val it : int = 0 > compare (10,30) (10,20);; val it : int = 1 > compare (2,30) (10,20);; val it : int = -1
この構造的比較演算による比較は、組み込みの比較命令を使うので非常に高速です。また、この比較演算の動作はSystem.IComarableを自分で実装することでカスタマイズすることができます。
F#の標準ライブラリにはオプション型(option type)という便利な型が定義されています。この型は、ジェネリックなメンバをもつdiscriminated unionで、以下のようなメンバを持ちます。
type Option<'a> = | None | Some of 'a
オプション型は、無効値をとりうる値を表現したい場合に利用されます。その値が何らかの有効値である場合には、値はSomeとなり、'T型のパラメータにその有効値を格納します。一方、その値が無効値である場合には、値はNoneとなります。Noneの場合はパラメータを持たないので、値は何も格納しません。